在对做压力时,我们需要对sql语句做一个参数化的处理。
_Random:产生随机数
_threadNum:线程号最为参数值
_CSVRead:从csv文件中读取,可以指定读取的列
_StringFromFile:从文件中读取,一次读取一行,文件的格式必须是.dat文件
以下面的select语句为例,对dfhruefhrhg对参数化处理,使每次执行时读取不同值
select b.sql_text from hr.aa a,hr.bb b where a.sql_id=b.sql_id and a.sql_id=‘dfhruefhrhg’
步骤1:准备一个csv文件存放参数值,hr.aa表中sql_id的值最为参数
SQL>spool e:sql_id.sql
SQL>select sql_id from hr.aa group by sql_id;
SQL>spool off;
将sql_id.sql文件整理后重命名为sql_id.csv
步骤2:添加一个用户自定义变量
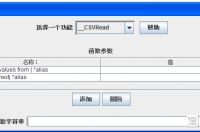
1.按ctrl+F快捷键弹出函数助手,选择_CSVRead函数
其中CSV file to get values from填写csv文件的绝对路劲
填写完之后点击生成
2.添加一个用户自定义变量:线程组–>添加–>配置原件–>用户自定义变量
名称取为sql_id,变量值为上一步产生的函数字符串
步骤3:在jdbc请求中将dfhruefhrhg替换为产生的函数字符串${__CSVRead(Esql_id.csv,0)}
select b.sql_text from hr.aa a,hr.bb b where a.sql_id=b.sql_id and a.sql_id=‘${__CSVRead(Esql_id.csv,0)}"
变量值为${__CSVRead(Esql_id.csv,0)}
变量类型为varchar
步骤4:添加“察看结果树”,点击运行