混合现实和移动机器人技术的进步有望彻底改变我们未来对物理世界的看法和交互方式。今天,MR设备可以叠加与我们周围世界相关的数字内容。要做到这一点,MR设备需要确定它们相对于物理世界相关的精确位置。
我们将其称为camera定位(或camera姿态估计),而它同时是MR,无人机,自动驾驶汽车和移动机器人的核心任务。由于GPS不支持室内,并且对于下一代混合现实和自动驾驶平台而言不够精确,因此MR设备必须利用摄像头图像来确定其位于室内的位置。camera定位技术需要访问场景的3D数字映射。尽管图像不与所述的映射一起存储,但如果能够访问它们,系统有时能够推断出关于场景的敏感信息。这种敏感信息可能包括有关空间的几何形状,外观和布局,以及空间中的对象。
随着企业正竞相为MR系统构建所需的“MR云”,公众越来越关注在家庭,办公室,医院,学校和工业等敏感环境中的隐私和安全隐患。但考虑到MR技术将实现广泛的采用,令人惊讶的是,大家很少关注MR隐私和安全隐患的关键性质。
为解决相关的隐私问题,由微软和学术人员组成的科学家团队一直在研究新的算法技术。他们将在6月16日至20日举行的IEEE计算机视觉和模式识别大会中展示两篇论文研究。在第一篇论文中,他们指出camera定位所需的3D点云和功能容易出现新型隐私攻击。这项研究旨在提醒社区新的隐私影响。在第二篇论文中,团队提出了一个新的研究问题:基于隐私保护图像的定位问题。他们同时提出了一个解决方案,其涉及以隐藏场景几何形状的方式来对3D点进行几何变换,从而防御新的隐私攻击并依然允许人们根据图像有效且准确地计算camera姿态。
下面是映维网的具体整理:
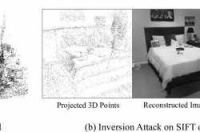
图1(a)是基于图像的传统定位方法,它需要场景的3D点云图,而这种点云有可能会泄露机密的场景信息。图1(b),针对3D点云图的新型隐私攻击可以重建场景的详细图像。
为了向社区提醒隐私问题,在佛罗里达大学的Francesco Pittaluga和Sanjeev J. Koppal,以及微软研究的Sing Bing Kang和Sudipta N. Sinha在《Revealing Scenes by Inverting Structure from Motion Reconstructions》中指出,即便源图像已被丢弃,3D点云所保留的信息都足以重建场景的详细图像。他们利用深度神经网络来重建场景的彩色图像。给定稀疏3D点的2D投影,及其在特定视点中的SIFT特征,网络能够输出场景的彩色图像(参见图1)。底层模型由多个U-Nets组成(常用语计算机视觉的神经网络通用架构)。令人惊讶的是,即便当诸如颜色,可见性等3D点的关键属性不存在时,或者当映射中的点稀疏且不规则地分布时,模型都能够重建出可识别的图像。他们在各种各样的场景中证明了攻击的可行性。最后,团队证明了模型甚至可以重建新的场景视图,并且可以生成私人空间的虚拟游览体验。
图2:3D线云表示可通过隐藏场景几何图形来保护用户隐私。隐私攻击受到阻碍,而系统依然可以进行准确有效的camera定位
与此同时,团队一直在研究新的camera姿态估算算法。尽管行业已经存在用于保护隐私的识别方法,但它们不能用于camera姿态估计,或MR和机器人中的其他3D计算机视觉任务。在《Privacy Preserving Images-Based Localization》这篇论文中,Kang,Sinha,苏黎世联邦理工学院的Pablo Speciale,以及苏黎世微软混合现实和人工智能实验室的JohannesSchönberger和Marc Pollefeys探讨了如何在避免泄露隐私信息的同时进行准备的camera定位。他们开发了一个保护隐私图像的定位解决方案:将映射中的3D点整合成随机定向的3D线。随后丢弃3D点。他们将这种新的映射表示称为3D线云(见图2)。值得注意的是,线云依然可以准确找到camera位置,因为2D图像点和3D线之间的对应能够提供足够的几何约束,并实现稳定和精确的camera姿态估计。
研究人员在一系列的环境中评估了他们的方法,并证明了其具有非常高的实用性。微软表示:“我们很高兴这项技术能够解决MR中的一些用户和企业隐私问题。所述技术可允许用户向第三方应用程序分享映射,但无需担心隐私问题。这同时能够减轻位置信息无意泄露后的危险性。”团队同时在研究将运行在云端的隐私保护算法。
研究人员将在本月举行的IEEE计算机视觉和模式识别大会中展示具体的研究。
原文链接:https://yivian.com/news/62333.html
来源:映维网



